Memory 2.0: Attentive Memory 2012-02-29
Continuing my series of posts on cognitive neuroscience of memory. In this post, I first give an overview of attentive memory, some examples of attentive memory failures, and then end with some thoughts on how we might want to support attentive memory in our design of interfaces and tools.
The frontal lobes is the most modern addition to the human brain, providing facilities for planning and reasoning about everyday tasks and social situations. Within the prefrontal cortex (PFC), lies amazing circuity for maintaining attention on important items during a task.
Attentive Memory
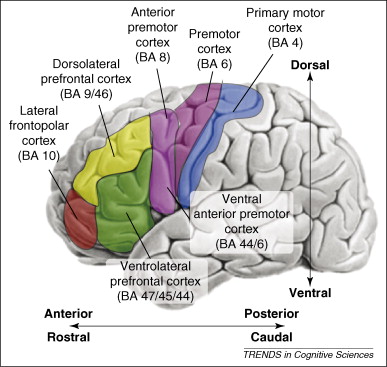
Attentive memory holds conscious memories that can be freely attended to. Within it, goals, plans, and task-relevant items can be sustained for substantial periods of time. Attentive memory is found in the ventrolateral and dorsolateral prefrontal cortex, a region situated in the anterior portion of the brain’s frontal lobe. One theory is that these regions provide the ability to maintain attention on modality-specific specific information such as visual targets in spatial locations or verbal information.
Attentive memory has two complementary operations with corresponding neural mechanisms: focusing and filtering.
Focusing
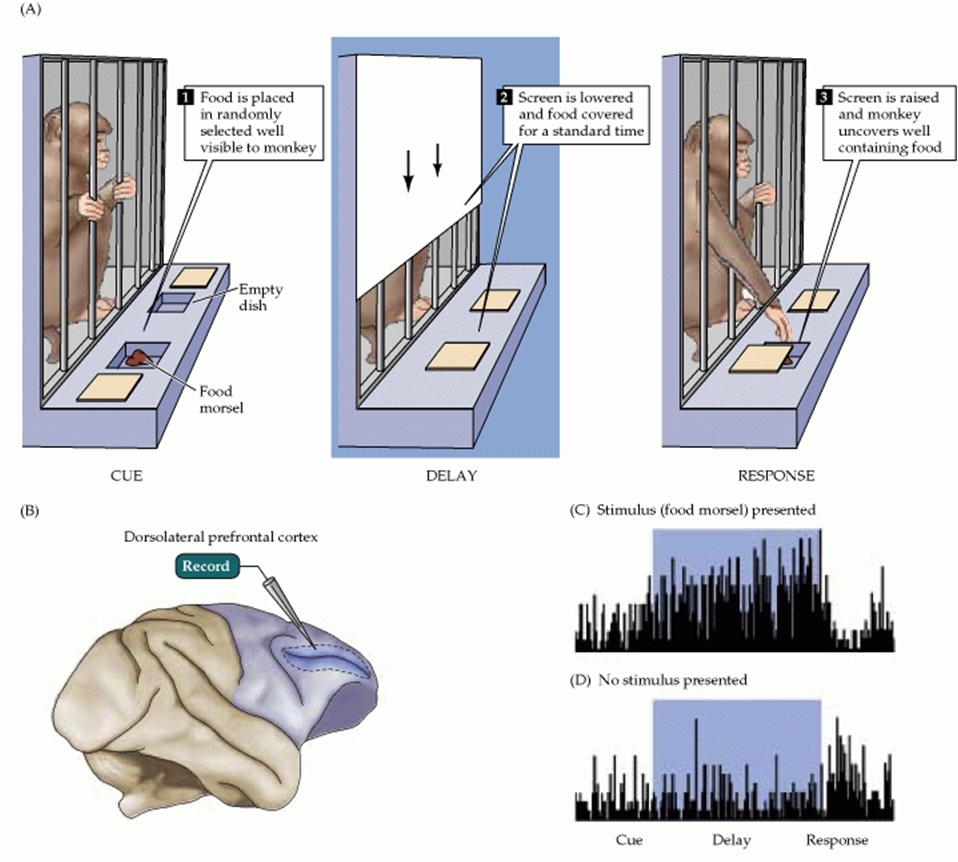
The ability to maintain focus on items has been well studied in the PFC of primates and humans. In early studies of monkey brains, when a food reward was shown to a monkey and then subsequently hidden for a delay period, persistent firing of neurons in the PFC was sustained during the delay period. Despite distracting stimuli, the monkey could recall the location of the food reward. However, monkeys with damage to the PFC could not maintain attention and performed poorly at recalling the location of the food [Fuster 71].
A human equivalent of these monkeys has been found in one patient, Clive Wearing. After a viral infection that destroyed much of his PFC and hippocampus, the patient could no longer attend to any memory longer than 30 seconds [Wearing 2006]. Definitely worth watching the documentaries: part 2a, part 2b,part 2c, part 2d; and more recently: “Man with the 30 second memory”.
Memory 2.0, A prelude. 2012-02-07
Why are we still using ideas about memory from the 60’s to build programming tools?
As with the beginning of most fields of research, discovery is born from stumbles in the dark. Then beacons appear–theoretical stakes laid by early pioneers, a way for researchers to make sure-footed progress. But we were not meant to settle here.
Up to now, we have been building program tools based on conceptual models decades old, founded on psychology research that is even older. As one of the authors of a prominent conceptual model recently stated, “These models are being used long-past their shelf-life”.
For the programmer, almost no tool exceeds that of the brain and its ability for memory. Despite this simple observation, almost no programming tool is built based on our understanding of the brain and its ability for memory. Our conceptual models and theories still hold outdated views on the brain and memory.
In my research, I building conceptual models for supporting programming tasks based on a theory that understanding the cognitive neuroscience of human memory is essential for understanding how to build tools that support programmers. In doing so, I abstract out some key concepts and principles about human memory from modern neuroscience literature, in a manner that (hopefully) allows researchers and toolsmiths to build better programming tools.
In no uncertain terms, programmers need our help. Despite human memory’s remarkable ability, memory stressors are chipping away at programmer’s productivity. Interruption devastates memory and continues to make tasks twice as long to perform, and have twice as many errors [Czerwinski 04]. In a study of such interruptions, Parnin and Rugaber [Parnin 10] analyzed interaction logs of 10,000 programming sessions from 86 programmers and found that in a typical day, developers rarely are able to program in long continuous sessions. Instead, a developer’s day is fragmented into many short sessions (15-30 minutes) interspersed with occasional longer ones (1-2 hours). Further, at the start of each of the longer sessions, a programmer often spends a significant amount of time (15-30 minutes) reconstructing working context before resuming coding.
Age is also becoming another relevant stressor on memory; as demyelination [Andrews-Hanna 07] begins just a few years completing a college degree, followed by the specter of ageism. As Stephenson put, Software development, like professional sports, has a way of making thirty-year-old men feel decrepit [Snow Crash]. Take a stroll down a google or EA office, teeming with thousands of 20-somethings, and handfuls of “ancient ones”.
Auto-blogging - Publishing a coding task to wordpress. 2011-11-02
UPDATE:
Commonly, we need to perform a programming task that we do not know how to do or is not well-documented. Collectively, we perform these reoccurring programming tasks all the time, but only a few of us actively blog or contribute to sites like stackoverflow with answers. Thus, there are many remaining programming tasks, which are never documented for other teammates (on internal company blogs), don’t have any (good) official documentation, or discussion on blogs or Q&A; sites.
If we can make it easier for people to blog, or share these experiences, then collectively we can make learning about these things a whole lot easier. This might also make other situations, like a task-hand off to another teammate easier. This post is a research demonstration of a technique that analyzes the coding history of a programmer and then automatically creates a blog summary of how they programmed that bit of functionality. This is still at the earliest stages, but I hope there is a lot of room for growth and expansion.
Check out the demonstration, and then some of the next steps below.
Proof-of-concept: Auto-generating a coding task blog post
This is an semi-automatically generated blog post created with the aid of some research tools I’m developing!
First, I’ll show you how this post got here, and then use it to illustrate a recent coding task involving programmatically “publishing” a blog post from C# code.
Auto-generating code snippets in Visual Studio.
First, click “Auto-Populate” (by default looks at most recent activity in 24 hours).
Napkin Idea: Code Tabs 2011-10-18
Tabs were introduced in Visual Studio 2003 (although addins existed for Visual Studio 6). This is how they look now in Visual Studio 2010:

My best guess is that developer’s have a love/hate relationship with tabs. They’re great when they work, but many times they get cluttered, and developers have to go nuclear on them (“Close All Tabs”).
A simple fact is that many times developers simply forget what the heck was in the tab. Research backs this up: Ko et. al found developers relied on environmental cues such as tab placement and scroll bar positions in documents to know where anything is. In work looking at recorded navigation history of developers, commonly there will be patterns where developers will frantically switch around documents (“navigational jitter”) as they’re trying to find the right tab.
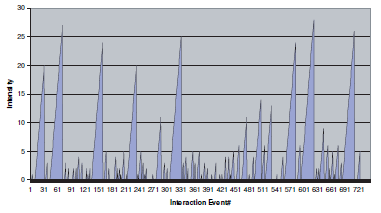
A second problem with development is context explosion. A developer’s task context typically involves a few files, but will quickly explode when exploring, debugging or searching through files. Above is a snapshot of one developer’s session measuring the number of actions (edits,clicks,etc) taking on a file before switching. You may notice that the developer focuses on one element for a while, before jumping around several locations until settling in the next major location of focus.
The napkin idea
What if we did two things. First, let’s put a preview of the content in the tab. Memory research suggests that “names” are poor cues for recall. Second, let’s associate the tab with the major action it was involved with.
Update (New Screenshot):

Building a Visual Studio History Extension Part #2 2011-10-07
Continuing my last post on creating a basic history extension, let’s actually do something! Here, we dive into capturing events to code documents in Visual Studio and using that to create a help build a local code history for edits.
First, let’s make a new SaveListener class that will subscribe to Running Document Table events.
class SaveListener : IVsRunningDocTableEvents3 {
We need to request the SVsRunningDocumentTable service and subscribe to it’s events.
IVsRunningDocumentTable m_RDT;
uint m_rdtCookie = 0;
public bool Register()
{
// Register events for running document table.
m_RDT = (IVsRunningDocumentTable)Package.GetGlobalService(typeof(SVsRunningDocumentTable));
m_RDT.AdviseRunningDocTableEvents(this, out m_rdtCookie);
return true;
}